第5课:统计与文本生成——AI如何“接龙”?
【学习目标】
1. 理解基于前文进行预测的基本原理
2. 能够通过统计方法构建简单的文本生成模型
3. 分析简单统计模型的局限性及大语言模型的改进方向
4. 评价统计方法在文本生成中的价值与不足
【情境导入】
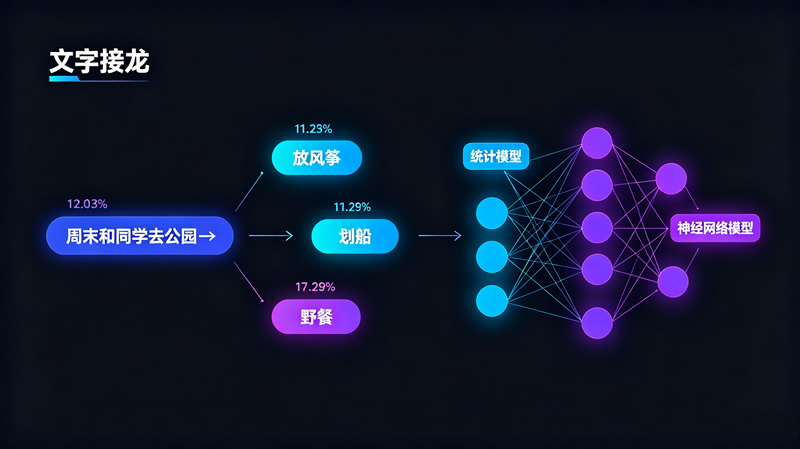
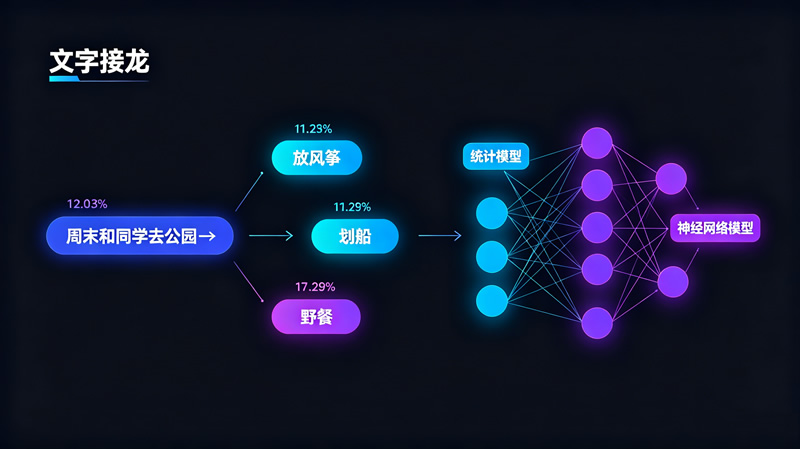
当你使用智能输入法,刚输入“周末和同学去公园”,它便自动提示“放风筝”“划船”“野餐”等词语。这些仿佛能“猜透你心思”的智能提示,其核心正是基于统计的预测模型。系统通过分析海量文本数据,计算出在“周末去公园”后面,出现“放风筝”的概率最高。今天,我们就来揭开统计与文本生成的奥秘,看看AI是如何通过“接龙”的方式逐步掌握人类语言习惯的。
【知识大揭秘】
概念引入:基于前文的预测
文本生成的核心是自动预测下一个词。前文为预测后文提供了关键依据。看到“小鱼”时我们会选“游泳”,看到“小猫”时会选“奔跑”——这种选择源于生活中的共同认知经验,而AI则通过学习海量文本中的搭配规律来实现同样的效果。
深度解析:从相邻字词统计到文本生成
通过统计任意两个词语相邻出现的次数,可以计算出它们之间的搭配强度,从而实现对下一个词的预测。当训练数据足够多、统计表足够庞大时,机器对字词组合规律的掌握就会更全面,生成的文本也会更加丰富与自然。但简单统计模型仅依据字词共现次数进行预测,没有处理对仗、押韵、意象连贯等诗歌要素。
案例时间:从“小鱼游泳”到“大模型写诗”——文本生成的进化之路
最早的文本生成只能基于相邻字词的统计规律生成简单句子,如“小鱼游泳”。当前的大语言模型则基于人工神经网络,能捕捉字词之间更深层次、更复杂的关系,例如理解“明月”与“玉盘”指的是月亮,也知道“春风”常与“和煦”相连。尽管技术基础不同,但核心预测思想一致:根据已有的文字,预测下一个最可能的字词。
知识小结:文本生成的两个关键认知
第一,文本生成的核心是“根据前文预测后文”,这是所有语言模型的共同基础;第二,从简单统计到大语言模型,技术不断进化,但预测思想一脉相承。
【AI看图学】
【动手练一练】
活动:动手“算出”诗句
步骤:
1. 给定一组古诗语料,统计相邻两字出现的次数,构建统计表
2. 根据统计表,从“深”开始接龙,生成五言句和七言句
3. 尝试创建新的关联组合,生成全新的诗句
4. 对比分析:统计模型生成的诗句与真实古诗有什么差异?
工具/平台:工具/平台:纸笔、计算器,或使用Excel进行统计
预期成果:预期成果:一组由统计方法生成的诗句,附带对生成质量的分析
【想一想·辨一辨】
1. 简单统计模型生成的诗句往往“通顺但不动人”,你认为要生成真正好的诗歌,模型还需要学习哪些更复杂的因素?
2. 当前的大语言模型生成的文章看起来很“聪明”,但它真的“理解”了文本吗?你怎么看?
【拓展阅读·前沿视窗】
了解“语言模型”的发展史:从最早的n-gram模型到循环神经网络(RNN),再到当前的Transformer架构。每一次技术迭代都让模型能够“看到”更远的上下文,生成更连贯的文本。NLP工程师是AI领域的核心职业,他们让机器更好地理解人类语言。
学完本课了?来检验一下学习成果吧!
🎯 去练习


