第4课:机器如何拆解语言?——从分词到词元
【学习目标】
1. 理解词元(token)的概念及其作为AI处理语言基本单位的作用
2. 能够对比人类与机器在分词方法上的主要差异
3. 分析BPE算法自动构建词表的核心思想
4. 评价不同分词策略对AI理解语言的影响
【情境导入】
当你向聊天框输入“人工智能正在改变生活”时,你能轻松识别出“人工智能”“正在”“改变”“生活”这些有独立含义的词语。但对机器来说,这却是一项挑战。面对“南京市长江大桥”,机器会拆分成“南京市”“长江大桥”还是“南京”“市长”“江大桥”?这个看似简单的问题,实际上是AI理解语言的第一步,也是最关键的一步。
【知识大揭秘】
概念引入:词元——AI的“语言砖石”
计算机处理信息的基本单位是字节,而AI处理语言的基本单位则是词元(token)。词元通常是一个子词单位,一个完整的词往往会被拆分为多个词元。例如英文“fortunately”可能被拆分为“for”“tun”“ate”“ly”四个词元;中文“数据库”可能被拆分为“数据”和“库”两个词元。
深度解析:人类分词 vs 机器分词
人类分词主要依赖语言知识和语感,而机器的分词策略则根据任务需求灵活调整。为可视化设计时,需要切分出贴近人类认知的整词形式;为模型处理设计时,则经常得到便于机器学习的子词形式。分词方式的选择,直接决定了AI“看到”和理解世界的方式。
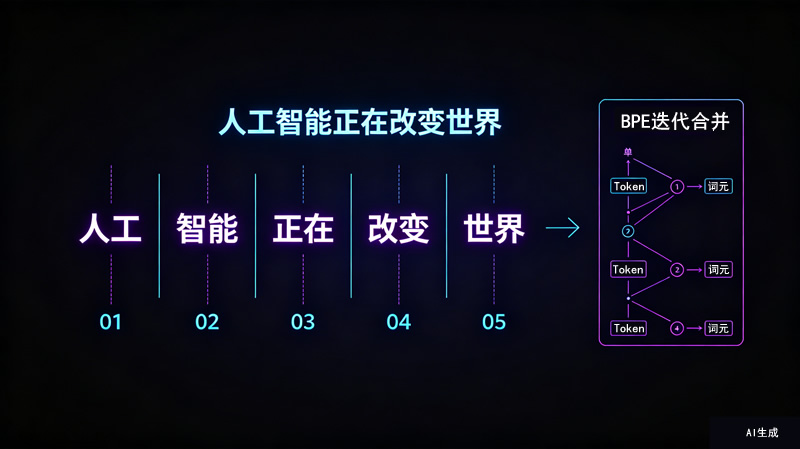
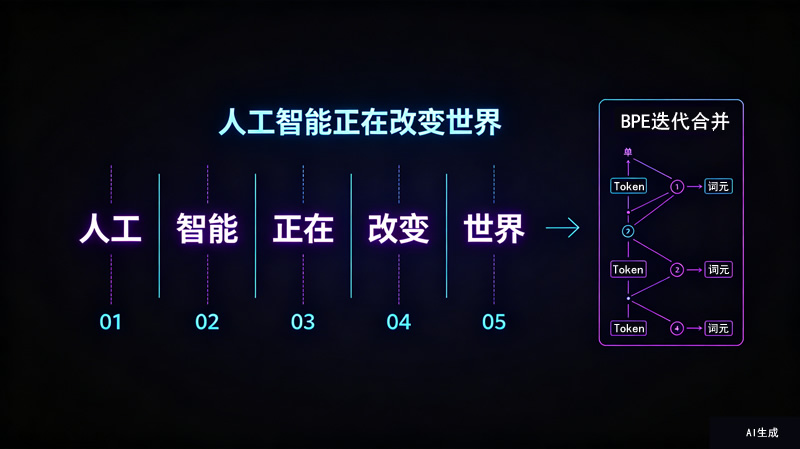
案例时间:BPE算法如何“算出”词元
BPE(字节对编码)是当前主流大语言模型采用的词表构建方法。它的核心思想是:从单个字符开始,反复合并出现次数最多的相邻字符对,逐步构建出更长的词元。例如在“人工智能正在改变世界”等语料中,“人”+“工”出现次数最多,先合并为“人工”;“智”+“能”其次,合并为“智能”。即使不理解语义,机器也能基于统计规律从文本中“算出”不同形式的词元。
知识小结:分词的三个关键认知
第一,词元是AI处理语言的基本单位,它不等于人类认知中的“词”;第二,机器分词并非基于对语义的“理解”,其核心机制在于统计与概率计算;第三,分词方式的选择直接影响AI理解语言的方式和质量。
【AI看图学】
【动手练一练】
活动:体验不同分词工具的差异
步骤:
1. 在DeepSeek中输入“请将以下句子进行分词:南京市长江大桥”,观察其分词结果
2. 尝试多个歧义句(如“结婚的和尚未结婚的”),观察不同工具的分词差异
3. 分析为什么同一句子的分词结果可能不同
工具/平台:工具/平台:DeepSeek、jieba在线分词工具
预期成果:预期成果:分词对比分析表,包含不同工具对同一文本的分词结果和差异分析
【想一想·辨一辨】
1. 如果一个大语言模型把“人工智能”拆分成“人”“工”“智”“能”四个词元,而另一个模型保持为“人工智能”一个词元,哪种更好?为什么?
2. 机器分词不基于语义理解,而是基于统计规律。这意味着AI“理解”语言的方式与人类有本质区别。你认为这种区别会导致什么问题?
【拓展阅读·前沿视窗】
了解当前主流大语言模型使用的词表规模——例如GPT-4的词表包含约10万个词元,而中文词元的数量远少于英文词元,这导致中文处理的计算成本更高。自然语言处理工程师是AI领域的重要职业,他们负责设计和优化语言处理系统。
学完本课了?来检验一下学习成果吧!
🎯 去练习


