第8课:机器如何“反思”?——反馈数据与自我优化
【学习目标】
1. 理解具身智能通过行动后采集的数据反馈至感知、决策与行动环节,实现自主优化
2. 分析传统智能设备的模拟反馈与具身智能自主反馈的本质区别
3. 评价反馈闭环对具身智能持续进化的关键价值
【情境导入】
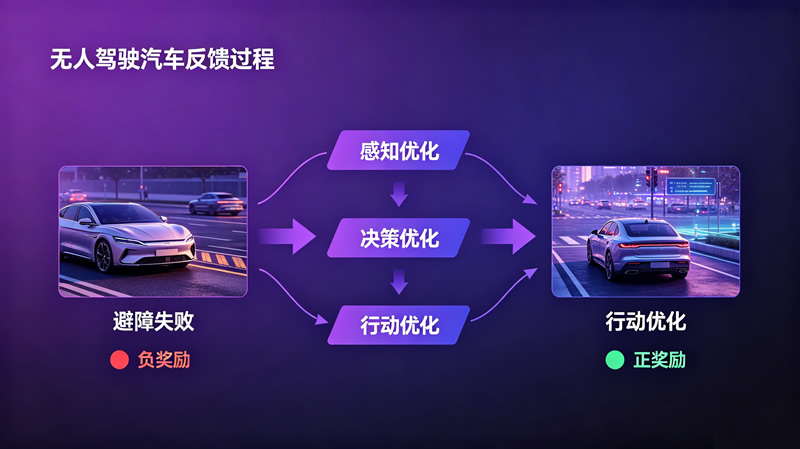
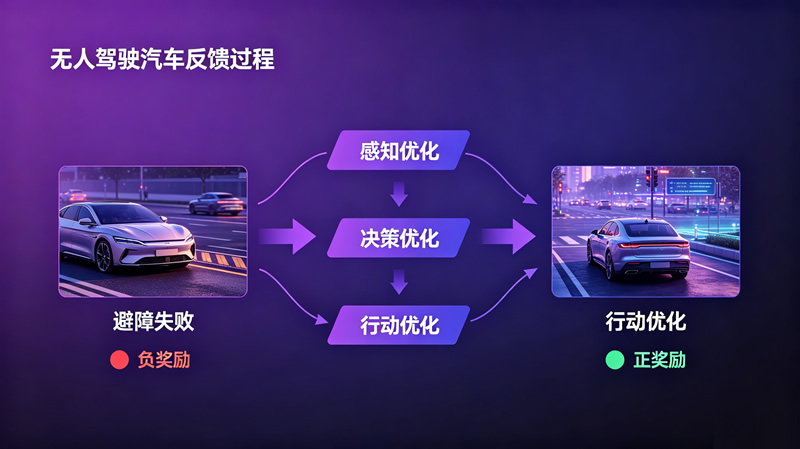
智能避障机器人第一次靠近障碍物时反应迟缓,通过传感器记录接近过程中的距离、速度等数据,在多次尝试中通过强化学习逐步学会提前减速;自动驾驶汽车会通过分析行驶轨迹数据,优化后续避障策略。这些从行动中学习的过程,正是具身智能反馈的重要价值:让具身智能不再重复相同的错误,而是持续优化行为。
【知识大揭秘】
概念引入:反馈——行动的“成绩单”
反馈是具身智能闭环的纽带,将一次行动的结束转化为下一次行动的改进。传统智能设备的反馈机制是被动的,通过传感器检测行动是否达成预设目标,并触发固定响应。具身智能的反馈机制则将过程数据和结果数据转化为正、负奖励信号,通过强化学习自主优化感知、决策与行动。
深度解析:两种反馈的三大差异
案例时间:无人驾驶汽车的“经验进化”
知识小结:反馈的三大特点
【AI看图学】
【动手练一练】
活动:智能磁吸小车避障反馈实验
活动目标:通过实践活动深化对本课知识的理解,培养动手能力和分析思维
步骤:
1. 配置MQTT无线遥控,连接智能磁吸小车和超声波传感器
2. 烧录预设控制程序,利用遥控器控制小车行进
3. 在不同距离障碍物场景中测试小车反馈(是否停止)
4. 分析小车的反馈是否能自主调整策略,对比具身智能的闭环反馈
工具/平台:智教玲珑板、超声波传感器、智能磁吸小车、MQTT服务器
预期成果:实践记录表,分析小车反馈的局限性,理解具身智能闭环反馈的价值
【想一想·辨一辨】
1. 如果一个具身智能设备只有“正奖励”而没有“负奖励”,它能学会避免错误吗?为什么?
2. 人类的“吃一堑长一智”和具身智能的“负奖励学习”有什么相似之处?
【拓展阅读·前沿视窗】
了解强化学习中的“经验回放”技术,它让具身智能能从历史行动数据中学习,而不必每次都在现实中试错。AI训练工程师是设计具身智能反馈学习机制的关键职业。
学完本课了?来检验一下学习成果吧!
🎯 去练习


