第4课:身体、大脑与经验——具身智能的三大核心要素
【学习目标】
1. 理解具身智能的核心三要素:具身本体、智能内核、环境交互,并能结合实例说明各自作用
2. 分析三要素之间的内在联系与协同关系
3. 评价具身智能“人—机—物”深度融合的关键特征与应用价值
【情境导入】
城市道路中,一辆无人驾驶汽车正平稳行驶。突然,前方路口有行人横穿马路,车辆立即减速避让;随后,不远处出现施工路段,它实时调整路线顺利通过。某智慧农场中,一台智能采摘机器人能够以精确的角度和力度,在确保不损伤藤蔓和果实的情况下自主采摘。这些设备为什么能像人类一样灵活应对复杂环境?它们由哪些核心部分组成?又是如何与人类、环境融为一体的?
【知识大揭秘】
概念引入:具身智能不是“AI+机器人”那么简单
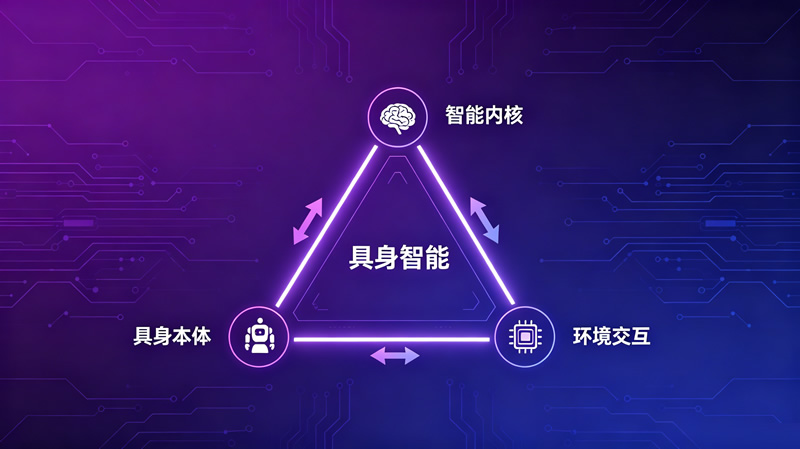
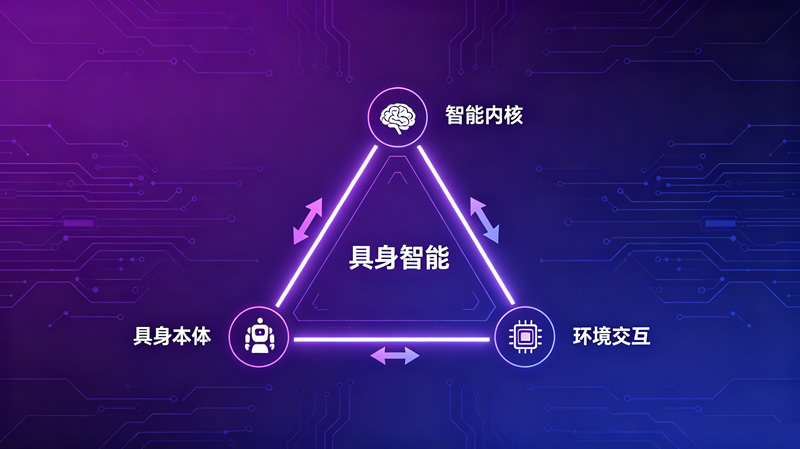
具身智能不仅仅是“人工智能+机器人”,而是人工智能通过物理本体与环境交互实现“知行合一”的综合智能。它的核心三要素包括:具身本体、智能内核、环境交互。这三者相互依存、缺一不可,共同构建了具身智能的完整能力体系。
深度解析:三要素的内涵与关系
案例时间:“我渴了”——一句话背后的三要素协同
知识小结:三要素的协同关系
【AI看图学】
【动手练一练】
活动:具身智能设备判断与分析
活动目标:通过实践活动深化对本课知识的理解,培养动手能力和分析思维
步骤:
1. 阅读两个场景:场景一是某餐厅的智能送餐机器人,只能按预设路线送菜,遇阻卡时停下播放语音提示;场景二是某医院的辅助运输机器人,能自主规划路线、实时调整绕行、扫描确认患者身份
2. 判断每个场景是否属于具身智能,并说明判断依据
3. 用三要素框架分析场景二中的具身本体、智能内核、环境交互分别体现在哪里
工具/平台:纸笔或PPT
预期成果:完成分析报告,包含判断结果和三要素分析
【想一想·辨一辨】
1. 如果要你设计一款能实现“人—机—物”深度融合的具身智能机器人,你希望它完成什么任务?它需要具备哪些能力?
2. 有人说:“只要算法足够强大,具身本体的形态不重要。”你同意吗?
【拓展阅读·前沿视窗】
了解视觉语言动作模型(VLA)的概念,它是具身智能“智能内核”的前沿技术,能同时理解视觉、语言和动作指令。关注人形机器人、无人驾驶汽车和无人机被称为未来生活的“智三样”,它们代表了具身本体在不同场景中的典型形态。
学完本课了?来检验一下学习成果吧!
🎯 去练习


