第11课:《文学遇上算法:K-MEANS分组魔法》
【学习目标】
• 了解K-MEANS聚类算法的核心步骤
• 掌握用特征差判断人物相似度的方法
• 体验数据驱动的文学分析过程
【情境导入】
《三国演义》中关羽千里走单骑,《水浒传》中宋江浔阳楼题反诗,《西游记》中孙悟空三打白骨精,《红楼梦》中林黛玉树下葬花……这些经典人物如果聚在一起开“名著聚会”,该怎么分组呢?按性别分?按朝代分?按性格分?有一种AI算法叫K-MEANS,它能根据人物的特征数据自动分组——不需要提前告诉它怎么分,它自己就能找到最合理的分组方式!让我们看看文学和算法碰撞出怎样的火花吧!
【知识大揭秘】
K-MEANS是一种“无监督学习”算法——它不需要提前标注好答案,而是自动发现数据中的分组规律。K-MEANS的核心步骤只有四步:
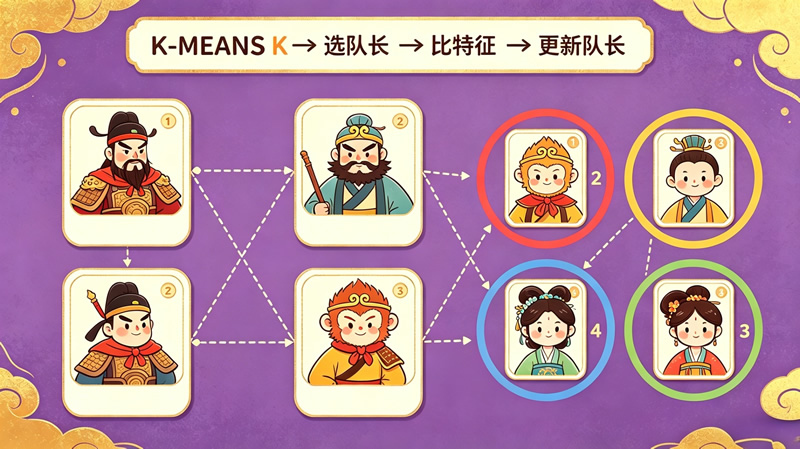
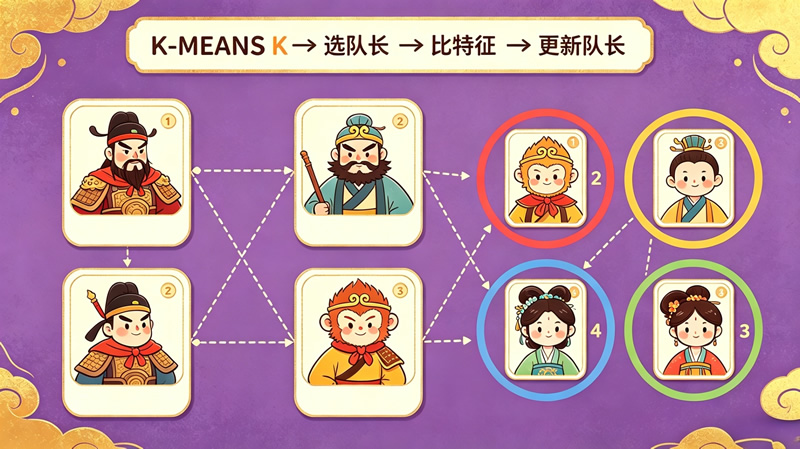
第一步:确定小队数(K值)。想分几个组就设K等于几。比如要把四大名著的人物分4个队,K就等于4。
第二步:选初始小队长。从所有人物中随机挑选K个人,每人当一个队的“初始小队长”。
第三步:比较像不像。计算每个人物和每个小队长的“特征差”——特征差越小,说明越相似。比如关羽和宋江的“忠义度”都很高,特征差就小;关羽和林黛玉的性格差异很大,特征差就大。每个人物选择和自己特征差最小的小队长组队。
第四步:更新小队长。组队完成后,每个队选出新的“中心人物”作为新小队长(特征最接近全队平均值的人)。然后重复第三步和第四步,直到分组不再变化为止。
K-MEANS的妙处在于:它完全根据数据特征来分组,不受人为偏见影响。比如它可能把关羽和武松分在一组(都是武将型),把诸葛亮和吴用分在一组(都是谋士型),这种分组方式可能和我们直觉不同,但从特征数据来看是最合理的。
【生活案例】AI帮你整理书架
小美的书架上有100本书,她想按类型整理但不知道怎么分。她把每本书的“特征”(页数、价格、是否小说、是否科普等)输入K-MEANS工具,设K=5,AI自动把100本书分成了5组:小说类、科普类、漫画类、历史类、工具书类。小美发现,有几本被AI分到“小说类”的书她原本以为是科普书,仔细一看确实有很强的故事性——AI的分组比她自己的分类更合理!
【AI看图学】
【动手玩一玩】
任务:用K-MEANS给名著人物分组
步骤:
1. 选择6-8个四大名著中你熟悉的人物
2. 为每个人物从3个维度打分(1-5分):武力值、智谋值、忠义值
3. 在纸上画坐标图,把人物按分数标注在图上
4. 尝试手动模拟K-MEANS:设K=2,随机选2个队长,按特征差分组
5. 重复迭代2-3次,观察分组是否稳定
预期结果:武力值高的人物(关羽、武松)会被分在一组,智谋值高的人物(诸葛亮、吴用)会被分在另一组。
【思考与延伸】
K-MEANS是“无监督学习”,不需要人告诉它答案。你觉得这种“自己发现规律”的方式和“人教它学”的方式各有什么优缺点?
学完本课了?来检验一下学习成果吧!
🎯 去练习


