第2课:《试错与进化:机器学习的秘密》
【学习目标】
• 理解机器学习中试错与优化的过程
• 掌握“数据—模型—预测”的机器学习基本逻辑
• 体验通过数据积累让模型不断改进的过程
【情境导入】
还记得你第一次学骑自行车摔倒的情景吗?摔倒了,爬起来再试;又摔了,再调整姿势……经过一次次试错,你终于学会了!机器学习的过程也充满了“试错”——只不过它摔倒的不是身体,而是判断错误。每一次错误,机器都会自动调整自己的“判断规则”,就像你调整骑车的姿势一样。今天,我们就来看看机器是如何通过“试错”不断进化的!
【知识大揭秘】
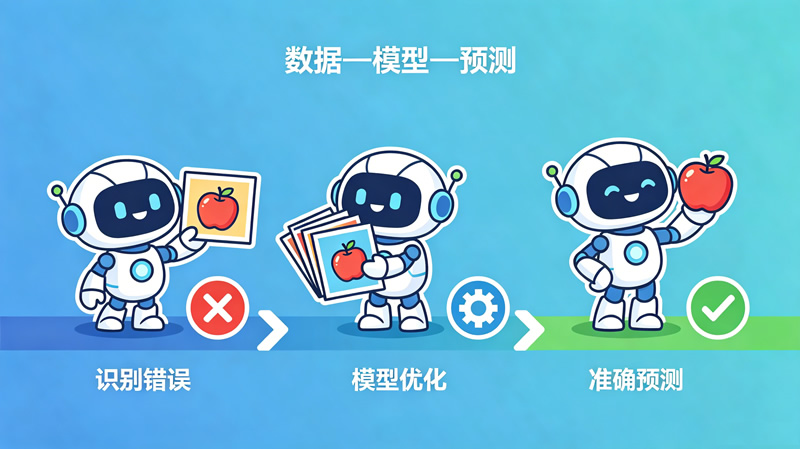
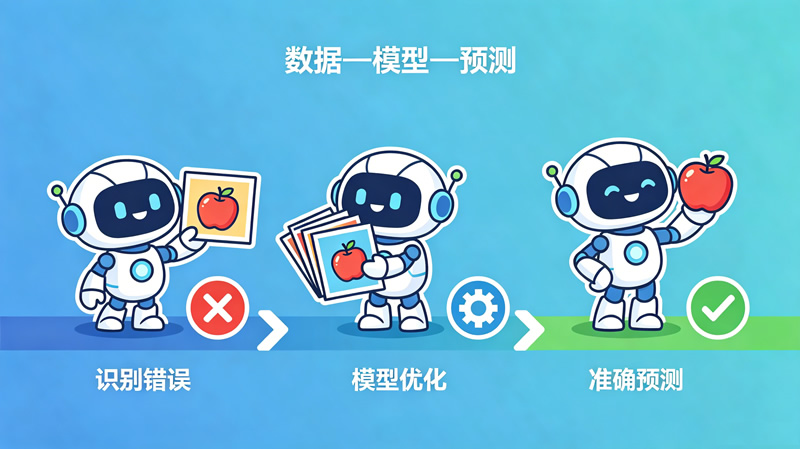
机器学习的核心逻辑可以用三个词概括:数据—模型—预测。
第一步:输入数据。就像你学骑自行车前要先“看”别人怎么骑一样,机器也需要先“看”大量的数据。比如,要让机器认出苹果,就需要给它看成千上万张苹果的照片,每张照片都标注着“这是苹果”。这些标注好的数据就是机器的“学习教材”。
第二步:训练模型。机器看了数据后,会在内部建立一个“判断模型”——就像你大脑里形成的“骑车感觉”。一开始,模型可能很不准确,把梨认成苹果,就像你刚学骑车时总是摔倒。但机器会自动比较自己的判断和正确答案的差异,然后调整模型参数,让下一次判断更准确。这个过程就叫“试错优化”。
第三步:做出预测。模型训练好后,当机器看到一张新的照片,它就能根据学到的规律做出判断——“这是苹果”或“这不是苹果”。就像你学会了骑车后,遇到转弯、避让行人都能应对自如。
【生活案例】AI识苹果的“进化史”
小明用AI图像识别工具测试识别苹果。一开始,AI只“吃”过10张苹果照片,它把红色的西红柿也认成了苹果(因为它们都是红色圆形的)。后来,小明给它看了更多不同角度、不同颜色的苹果照片,还加入了苹果和西红柿的对比图。经过反复训练,AI终于能准确区分苹果和西红柿了!这就是“数据越多,模型越准”的机器学习规律。
【AI看图学】
【动手玩一玩】
任务:体验机器的“试错进化”
步骤:
1. 打开AI图像识别工具(如百度识图、腾讯AI体验中心等)
2. 上传一张苹果的照片,记录AI的识别结果
3. 上传一张西红柿的照片,看看AI会不会混淆
4. 再上传一张青苹果(绿色)的照片,观察AI是否还能认出来
5. 记录每次识别的结果,分析AI在什么情况下容易犯错
预期结果:AI对常见的红苹果识别准确,但可能对青苹果或特殊品种识别不准。数据越全面,AI识别越准确。
【思考与延伸】
机器通过“试错”来学习,人类的试错和机器的试错有什么本质区别?机器的“错误”能像人类一样变成“经验”吗?
学完本课了?来检验一下学习成果吧!
🎯 去练习


